Stealth · deep-tech AI · method patent application in preparation
Attention, reimagined for stability.
A drop-in attention operator that stays stable where bare softmax needs
external crutches — at zero extra parameters and parity compute
cost. Not a quality miracle: a quieter, cheaper, more predictable way to train.
We're raising compute & the right partner for the first properly-budgeted 3B validation — our runs so far (601M–7B) were diagnostic-scale. Fund the experiment that de-risks the thesis, not a claim that it's already proven.
training-gradient stabilitystabilizer-free · high LR
Cpk = process-capability index (Six-Sigma): how consistently the process stays inside its limits — ≥1.33 is “capable”, <1 is out of spec
Measured, then controlled: we scanned this operator against a softmax twin, then re-measured against an independent-seed null — internal differences fell within run-to-run noise. Read the study
0extra parameters
≤ 1%measured compute tax
drop-inop-behaviour preserved (bf16 cos ≈ 0.99999)
seed-nullevery internal claim tested against run-to-run noise — the study
Pre-registeredDeterministic recomputemd5-sealed evidencegradient-norm SPC · Six-SigmaMethod patent application in preparation4-engineer team · ~20 yr
Two identities, one team
Revenue · today
An applied industrial-AI studio
Custom models, RAG & SFT, data→signal→model and digital-twin consulting, and quantitative
research infrastructure — grounded in ~20 years of multi-sector industrial & analytical
engineering. Real delivery, not slideware.
A new attention foundation — measured training stability, drop-in / zero-parameter,
capability-per-dollar. A fundable research thesis with a provenance-verified evidence chain (sha256-sealed artifacts, result-level checks);
method patent application in preparation.
Models we trained from scratch · published 30 Jul 2026
Two 1B models, trained from zero on 10.32B tokens each
Not fine-tunes of someone else’s checkpoint — pre-trained from
random initialisation, one full epoch, no data repetition, on a single H200. Then
instruction-tuned with a byte-identical recipe so the only variable between them is
the architecture. That control is what let us measure something new about SFT.
10.32Btokens each · one epoch, zero repetition
0.68%of weights SFT actually moved
48.4%judge-panel parity vs a same-size base model on ~1,750× more data
1 / 1,000,000how much SFT moved the memory in our own architecture
Tetracta-zkas-1B ● our architecture
Not a transformer — no attention. A γ-pole recurrent state with a
learned decay spectrum and a multiplicative saturation gate; at inference the state size does not
grow with sequence length. It completed 315,000 steps with zero skipped steps.
Because its components separate by function, we could read straight off the measurement where
instruction tuning went — and it left the memory frozen to one part in a million,
rewiring the output path instead. A transformer cannot show you that: attention weights carry memory
and processing together.
Published as measurements, not
weights. Every number is public; the equations, parameterisation and training recipe are not.
Deliberately vanilla — a standard 0.94B decoder-only transformer, published
in full: instruction-tuned weights, the raw pre-trained base, the reference implementation, the chat
template, and a tool runtime that actually executes the model’s tool calls.
It reaches judge-panel parity with a same-size base model trained on roughly 1,750×
more data — and it loses clearly to instruction-tuned rivals, which we publish
just as loudly. Its job is to be the open twin: every claim we make about the closed architecture is
re-runnable here.
Weights, code and the measured limitations
— including the one where it corrupts digits copying a tool result — are all on the card.
The honest headline: behaviour
alignment can be taught with very little data; knowledge and reasoning cannot — they need
scale. We won exactly the lanes SFT teaches (identity, honesty, chat, safety) and lost exactly the lanes
pre-training scale gives. Two architectures, measured independently, gave the same answer.
Technology & Research
Tetracta Rational Attention method patent application in preparation
A drop-in replacement for softmax attention. Unlike softmax, its weights need
not sum to one — so it can represent "spread little, commit to none" as well as "commit",
inspired by the way biological neurons compete and self-limit. We describe what it does,
and the effects we measured. We never disclose the recipe.
Parameterless stability strongest leg
Where bare softmax needs external stabilizers and still spikes at high learning rates,
rational stays calm — bounded by construction. This is our
strongest, most-measured result.
Drop-in · zero extra params
Identical parameter count, op-behaviour preserved (bf16 cosine ≈ 0.99999), lighter memory.
It replaces the softmax op in place and keeps the entire softmax ecosystem —
no architectural surgery, no retraining infrastructure, no new dependencies.
Capability per dollar
Hardware-tuned kernels keep MFU at parity with vanilla; the measured compute tax is ≤ 1%.
Higher learning-rate tolerance converts into steadier convergence on the same hardware —
fewer failed runs, less babysitting, lower training risk.
A modest, honest edge
A small, direction-consistent loss improvement at 3B and 7B — pre-registered and
md5-sealed. We sell direction, not a law, and best attribute it to learning-rate
headroom. No quality-leap claim.
Custom architectures, X-rayed worked example
We scanned a matched softmax/rational 1B pair with our own instrument — a bespoke, undisclosed
operator, not a HuggingFace model. First-pass internal differences looked striking; a pre-registered seed-null control
(three additional models) showed they were within run-to-run noise, and the figures were
corrected. The scan capability, and the control discipline, are the result.
Read the post-mortem
Methodology as a discipline
Pre-registration, deterministic recompute, gradient-norm SPC / Six-Sigma gates, md5
evidence chains. Diligence-grade rigour is the trust layer behind every number — and a
product in its own right.
Abstain research hypothesis
Because the weights need not sum to one, the operator can express "I'd rather not answer"
instead of always spreading full attention. Whether this reduces hallucination is
not yet proven — a controlled test was an honest null. It is exactly what
we are raising compute to test at 3B behavioural scale.
Engineering & compatibility
Drops into your entire softmax stack — proven, not promised
Rational replaces one operator and leaves everything else untouched. It was trained inside
a modern transformer stack — not in a toy setting — so it composes with the parts you already use.
Nothing in your pipeline has to change.
And it's a real system, not a slide: hand-tuned GPU kernels for H100 / H200, a multi-GPU (DDP)
training cockpit spanning 600M to 30B with resume, checkpointing and gradient-norm SPC, and a
rational-specific quantizer in progress for deployment. The measured efficiency numbers are below.
qk-norm
z-loss
µP
Muon + AdamW
Mixture-of-Experts
GQA
RoPE
bf16
gradient checkpointing
fused / Flash-style kernels
multi-GPU (DDP)
Positioned honestly next to prior work — Apple's FlashSigmoid, NVIDIA's nGPT, attention-sink /
softmax1 (Miller, 2023), PolaFormer, Microsoft's Differential Transformer. Each
ingredient exists somewhere in the literature; our angle is the intersection — a
bounded, drop-in, zero-param operator with a measured parameterless-stability
effect. We cite, we don't overclaim.
Results & Evidence
What we measured — and you can verify
Diagnostic-scale (sub-Chinchilla, ≤236M tokens) — provisional,
pre-registered, reproducible from sealed result files. Headline effects below; the downloadable
bundle lets you check the numbers yourself. No formula is disclosed.
Training-process defect rate — gradient-norm excursions (↓ better)stabilizer-free · high LR
softmax ~18%
rational ~0%
Process capability — Cpk (↑ better)stabilizer-free · high LR
softmax 0.30
rational ~1.59
Compute efficiency — MFU (parity is the result)tax ≤ 1%
softmax baseline
rational ≈ equal
Best-vs-best held-out loss edge — direction across scale (lower = rational ahead)3B · 7B
Read this honestly. Two width points establish a direction, not a scaling law. The
edge (~1.5% perplexity at 7B) is best attributed to learning-rate headroom, not a separate
nonlinearity advantage — at equal LR with both arms stabilized, softmax comes out a hair ahead
(+0.0153 bpb, the same order as the edge we report), which is why we call it parity.
Stability, dramatic
Stabilizer-free, bare softmax shows ~6.5× larger peak gradient norm (≈42.9 vs ≈6.6) and 29 spikes vs. 0 for rational — same body, optimizer, seed and data.
Scale tested
≈601M · 1B · 3B · 7B on H100 / H200. The clean comparison is 3B→7B; the decisive next step is a properly-budgeted 3B run where we expect rational to separate from vanilla.
The ask
Compute + capital + the right partner to convert provisional numbers into production-grade evidence, and to test downstream + abstain for the first time.
A worked example · how we keep ourselves honest
Twin loss curves, one operator apart — measured against seed noise.
We trained two 0.93B models under identical conditions — same seed,
same data in the same order, same schedule — changing exactly one component: the attention
operator. Their loss curves are twins. We scanned both with our own instrument, Model X-Ray, and
found striking internal differences. Then we ran the control that matters — an independent-seed
null on three newly trained models. The internal differences fell within the noise between two
ordinary runs, and the figures were corrected.
Full data and reasoning in the post-mortem.
We merged two specialists into a single 3B model with no training at the merge step: the two implanted skills jumped, and a 1,210-question head-to-head against the base — MMLU, ARC-Challenge, HellaSwag, Belebele in five languages — came back flat everywhere else (max |Δ| 1.3pp, within run noise). Surgery, not vibes: verified, failures published. Across ~10 experiments we validated when merging works at all: headroom × complementarity × proximity — all three measurable from the inside, before you merge.
Six pre-registered assassination attempts on our strongest claim, across four model families — two of our own claims died, one wrong verdict stayed visible in the report, and the fourth-family miss is published with the rest. The full autopsy, receipts included.
Tokens are what you pay for — and the same meaning costs wildly different amounts depending on the model. We measured 8 open tokenizers across 204 languages; off English the tax runs 2–3× and up to 10×. Now included in every X-Ray report — a tokenizer-level companion to the internal scan, not the scan itself. Efficiency, not quality — reproducible.
tieloss gap 0.001 bpb — smaller than the gap between two softmax seeds (0.002)
customa bespoke operator, X-rayed — not a HuggingFace model
5 modelstrained to test one claim against seed noise
in fullcontrol data published, favorable or not
The controlled experiment — one variable, nothing to confoundisolation by design
Validation bits-per-byte — a leaderboard cannot separate themlargest gap 0.0023 bpb (~0.2%)
softmax rational— identical seed, data order & schedule
How the scan works — inject, propagate, measure (no output grading)controlled perturbation
It measures what the model is, not what it says — two networks can emit identical text while routing internal signal in visibly different ways.
The seed-null control, and what it corrected. The first version of this section showed a
"4.4× quieter internals under int8" bar chart, a "dissipation signature," and an "84% of depth"
divergence. To test whether those were real or just the luck of one seed, we trained three more models
(two extra softmax seeds, one extra rational) and re-scanned. The result, with thresholds sealed in
advance:
int8 internal disturbance — spread between softmax seeds aloneseed-B 0.573 · seed-C 0.967 · the old "softmax" was 4.166
7.3× within one operator
The original softmax value was a high outlier. The softmax median sits below rational — the direction did not even survive. 4.4× retracted.
"84% of depth" divergence — seed pair vs operator pairboth span 84% of depth
seed 0.000324 ≈ operator 0.000307
Two ordinary softmax runs diverge internally as much as the operator swap does (ratio 1.06×). A ceiling indicator, exactly as our own note had warned. Retracted.
The routing-stability edge fell the same way (the rational replication landed inside the softmax band). Full numbers, per-model, in the post-mortem.
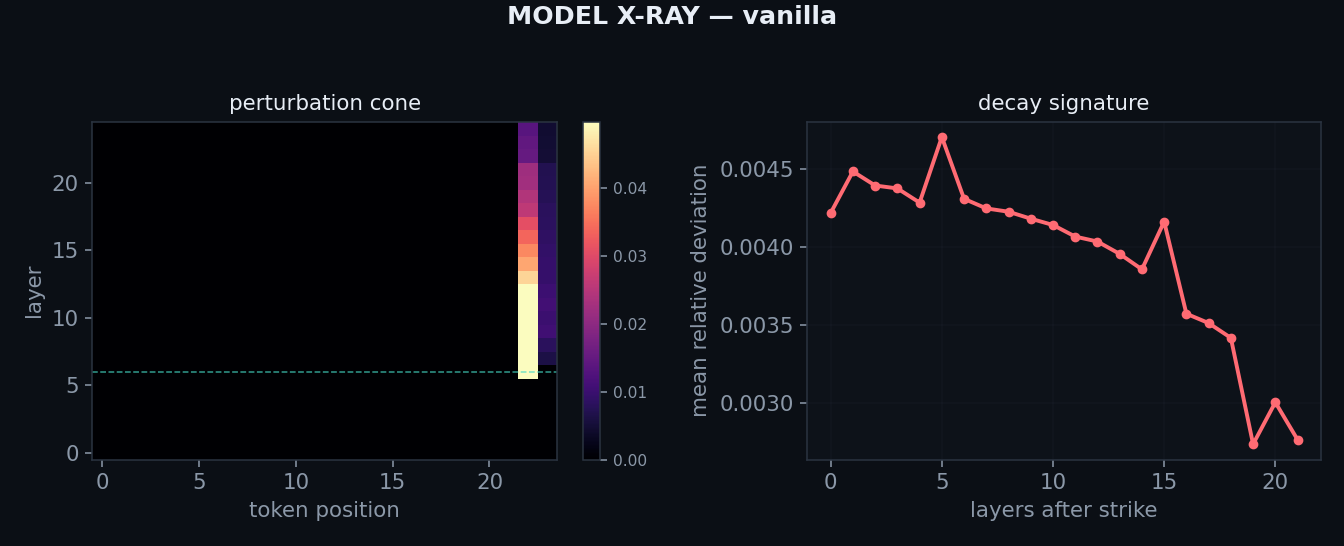
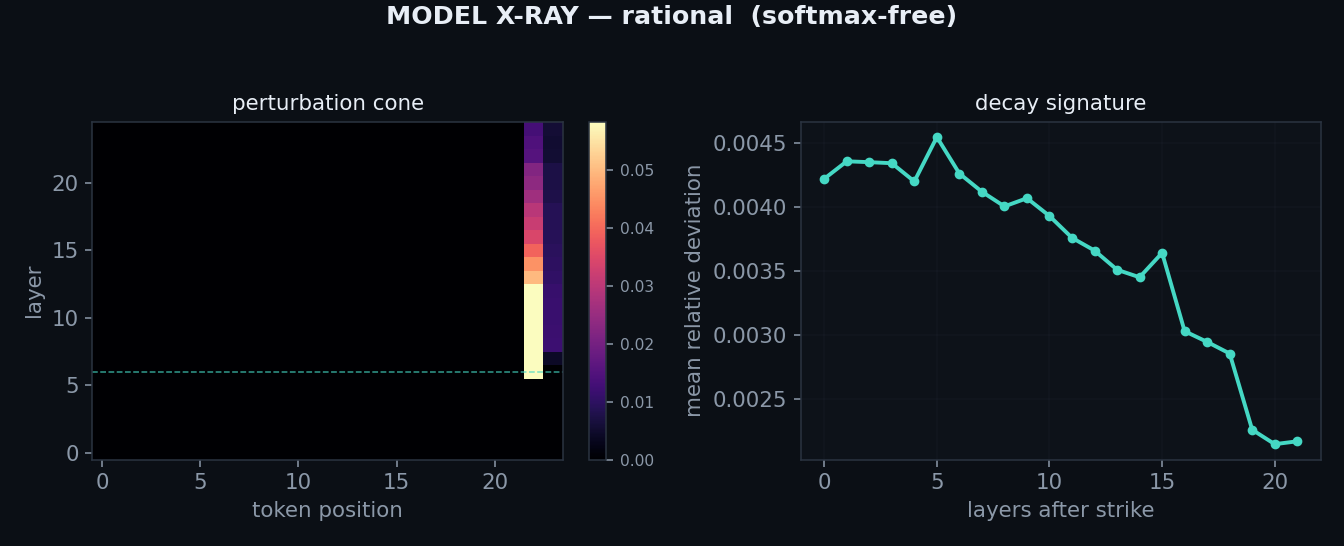
Actual scan output — perturbation cone & decay, per modelstep 30k · unretouched
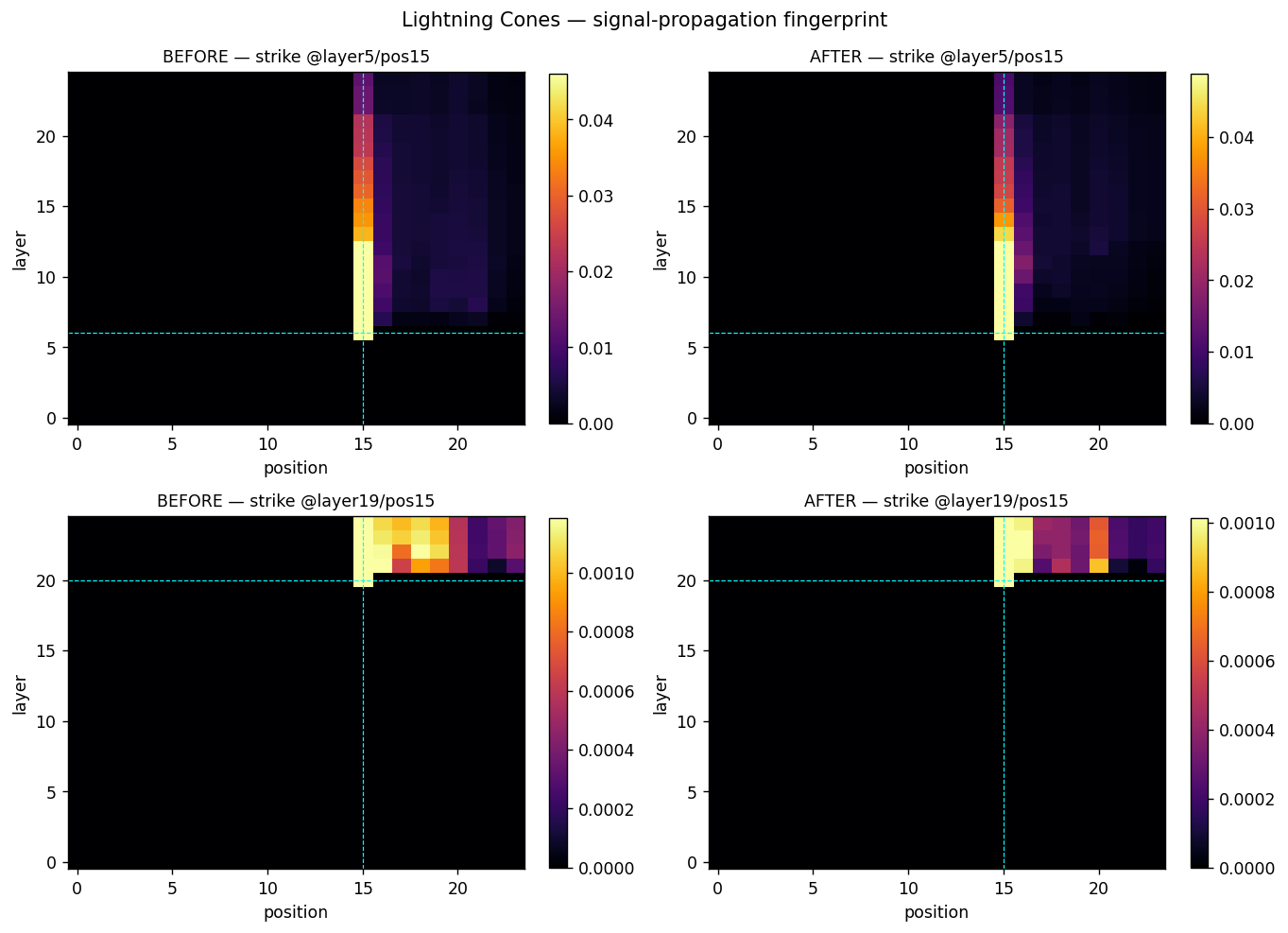
The comparison lens — signal-propagation fingerprints from the actual scan report378-probe scan · unretouched
Straight out of the instrument's comparison report, running unchanged on a bespoke architecture — the capability the retraction does not touch. Note: the per-model cone difference visible here did not survive the seed-null control; two ordinary softmax seeds differ by as much (see the post-mortem).
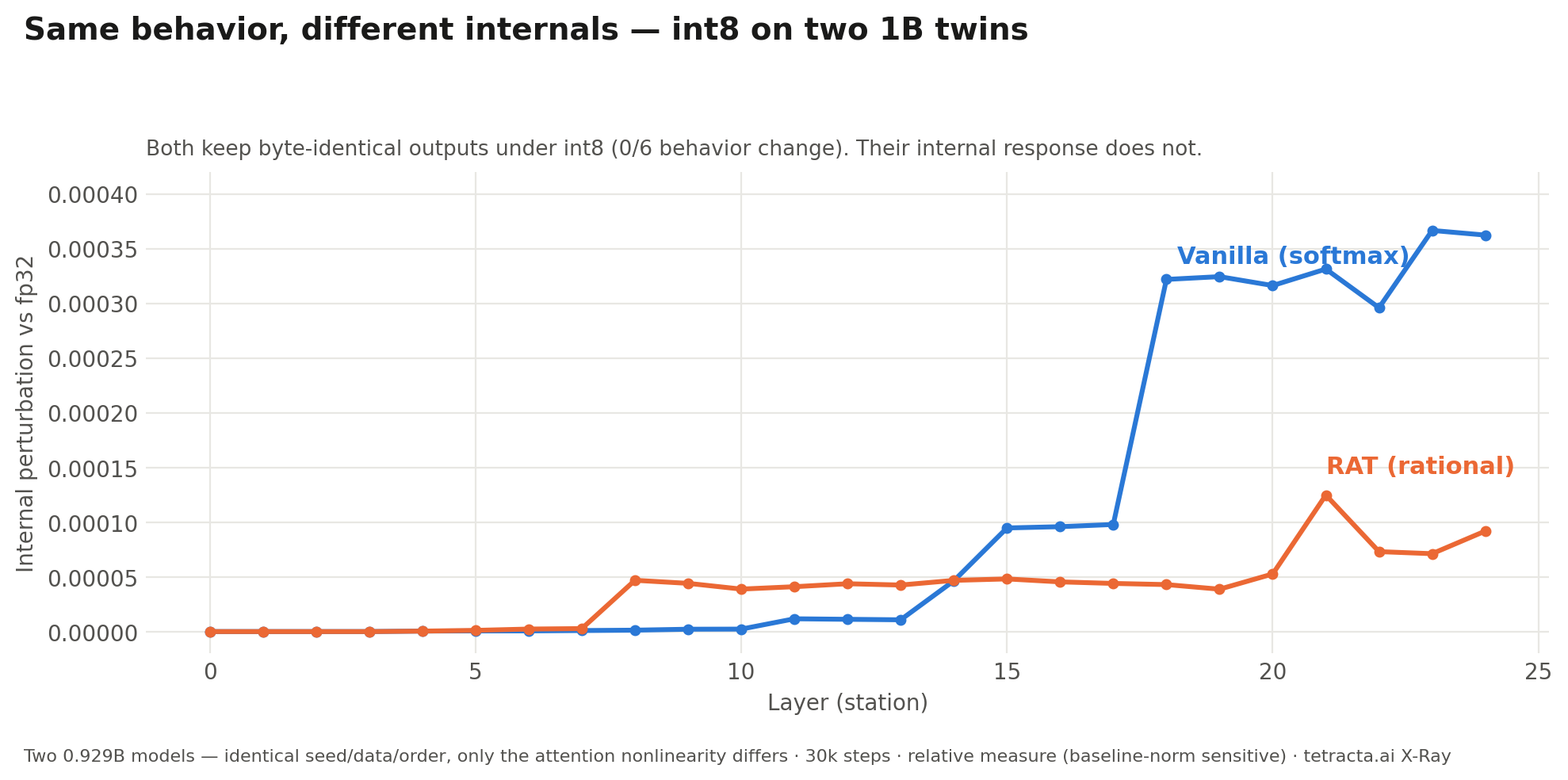
★ Same behavior, different internals — int8, re-run on the current production pipeline17 Jul 2026 · rs-1.3 · unretouched
Under int8 both twins keep byte-identical outputs (0/6 behavior change) — yet the X-ray resolves their per-layer internal responses as clearly different, deterministically. Per the seed-null control above, we attribute none of this to the architecture; what it demonstrates is the instrument: internal resolution that output-level evals cannot provide by construction. The scanner is now open to outside teams — X-Ray for LLMs →
The knowledge lens — and the null it handed uslogit-lens · 40 facts
The probe that killed our own hypothesis: at step 30k, fabricated entities (red) score as high as known facts (mint) in both arms — these young models know nothing yet, so no abstention claim can be made. We publish the instrument output that refuted us, unretouched.
What actually survived, stated plainly. The loss twins are real — and the control made that
claim stronger: the operator moves validation loss by less than the seed does (softmax-seed
spread 0.002 bpb > the 0.001 operator gap). The instrument scanning a bespoke, undisclosed operator
is real. A separate, seed-independent result also held: on a converged public MoE, real int8 kernels
flip about twice the routing decisions of the RTN simulation most audits use (~2.6% vs ~1.3%). What did
not survive: every claim that the two arms differ internally — those were within
seed noise, and are retracted.
What this really shows
Not that rational is better inside — the control refuted that.
It shows the control that separates a real signal from the luck of a seed, applied to our own
models first. That discipline is the diagnostics service, demonstrated on ourselves.
Two nulls we kept
The abstention hypothesis (a generation-budget artifact, p≈0.2) and now
the internal-difference headlines (within seed noise). Both published in full. A diagnostics lab that hides its
nulls is a marketing department.
Reproducible
The scanned checkpoints, X-ray summaries, brain-portraits and the weight-error
script are published for audit. The rational operator itself is not disclosed (method patent application in preparation).
Efficiency & ecosystem fit — engineered, not assumed
The new weighting is a custom op, so we built the systems around it —
hardware-tuned kernels, multi-GPU training, a deployment quantizer — and proved it composes with the modern
stack. Numbers below are measured on H100 / H200 across four model scales.
Provisional, diagnostic-scale — and no kernel internals are disclosed.
Scales actually run — 601M · 1B · 3B · 7B
Each isolated, pre-registered and reproducible
on H100 / H200. A working pipeline at billions of parameters — not a notebook demo.
Kernel + memory engineering (1B)
Hand-tuning the kernel, memory and optimizer paths more
than doubled our own implementation's training MFU (≈5.5% → ≈12%) and lifted its throughput ≈2.7× —
with model quality preserved.
Multi-GPU, end-to-end (3B)
A 3B model trained on 2×H200 via DDP at ≈17% MFU
and ≈25k tokens/s, checkpoint pulled back locally. Sustained ≈17–18% MFU holds at 7B.
Parity vs softmax — the honest result
Against a tuned softmax baseline the operator runs at
parity MFU for a measured ≤1% compute tax — not faster than softmax, but costing essentially
nothing extra. Provisionally ~1.2× capability per dollar.
Full ecosystem fit
Trained inside a modern stack — Muon + AdamW, µP, qk-norm,
z-loss, MoE, GQA, RoPE, bf16, gradient checkpointing, fused/Flash-style kernels, multi-GPU DDP. One operator
changes; nothing else has to.
Deployment quantizer (in progress)
Off-the-shelf tools assume a standard attention op, so
we are building a rational-specific quantizer (bf16 → int8 → 4-bit) that shrinks the model while preserving the
operator's stability.
Every number measured
Deterministic recompute, md5-sealed evidence, gradient-norm SPC —
the same disciplined harness behind the loss and stability results. No hand-waving.
Downloads · sanitized evidence
Don't trust us — verify
The full data — not summaries: every experiment,
every training step, every stability statistic. The only things withheld are the recipe
(formula, kernel internals, exact learning rates, schedule, SPC thresholds) and quant performance
figures — those are the IP. Checksums let you verify each file.
Want the full, mechanism-level technical brief, the internal raw-log evidence chain, and team
intros? Those are shared under NDA with qualified investors and partners —
request it here.
Capabilities · portfolio
What the team can build
Architectural range that signals one thing to investors and partners: this team
ships, it doesn't just talk. ML engineering is one capability among several — the rarer edge is
analytical engineering beyond ML.
Quantitative research engine ● live
A production-grade, walk-forward, multi-horizon cross-sectional pipeline — data → signal →
model → decision — producing models today, with leak-hardened, placebo-tested evaluation and
in-production SPC monitoring. (B2B, licensed institutions only; not investment advice.)
Industrial data & digital twins
Turning raw industrial/market data into decisions: predictive maintenance, time-series,
FFT / spectral signal analysis — and digital-twin data strategy (what to collect, how, the
real ROI) before a single model is built.
Brain-inspired architecture R&D
Research proof-of-concepts outside the softmax ecosystem (concept binding, spreading
activation). Early-stage, framed honestly — evidence of deep architectural flexibility, not
a shipped product.
Applied LLM systems
On-prem / data-sovereign assistants: Turkish-fluent SFT, tool-routing, live-web grounding
with sources, data-cleaning & QA pipelines, and a rigorous training-QC discipline.
Services · for partners
How we engage
Ordered by how quickly and reliably they create value. We work with partners
worldwide; Türkiye is our R&D base, not a ceiling. Under NDA we share enough to evaluate
seriously.
Custom model + SFT + RAGcore
A capable assistant on your data & tools — vanilla or rational (a stability / cost option, not a quality claim).
Training-data pipelinesdata
You bring raw text; we return a clean, deduplicated, domain-mixed, packed & tokenized training-ready stream — leak-checked, with a quality report. Your corpus, made model-ready by automated pipelines.
For companies and individuals: where the value is, which technical-business move to make. Results-oriented, realistic.
Quant research & signal infrastructureB2B
Engine licence / signal-as-research for licensed institutions only. Technology & rigour — not investment advice.
"Türkiye arm" / local presencepartnership
A TR R&D & delivery arm for a foreign firm or lab — including a frontier-lab office option. Our IP stays ours.
Training-stability / QC auditmethodology
We make training failures visible: pre-registered, reproducible, SPC-gated. Live-monitor your own runs.
Flexible / hourly micro-servicesfractional
Editorial, data & evaluation services for teams building Turkish models. Hourly / fractional.
Data-sovereign / on-prem assistantvertical
For regulated SMBs that can't use public APIs (KVKK / data residency): a grounded assistant behind your firewall.
IP · patent in preparation
Protected, narrowly and honestly
We show the effects; we never publish the mechanism. The patent is a defensive
shield, not a broad claim — the real moat is the recipe (trade secret) plus execution and
capability-per-dollar.
Narrow composition + measured effect
The filing covers a specific composition of bounded components together with a measured technical effect (training stability + learning-rate headroom) — not a broad formula monopoly.
Prior art, cited not hidden
We position openly against attention-sink / softmax1, FlashSigmoid, nGPT, PolaFormer and Differential Transformer. Hiding precedent fails diligence; citing it is the defensible position.
Recipe = trade secret
The formula, kernel internals, exact learning rates, schedule, and SPC thresholds are never disclosed — more valuable kept secret than patented. Effects are public; "how" is not.
Filing-first, then disclosure
Priority is filed before any public mechanism disclosure (EU/EPO has no grace period). This site carries effects only and is publication-safe; mechanism stays under NDA.
Public disclosure follows IP protection — by design. The moment our priority
filing is locked in, we'll open the full results and a technical paper to the world. Until then the
complete picture — methodology, raw-log evidence, and the team behind it — is already on the table
under NDA for serious investors and partners. The evidence is ready; the public
unveiling is just a matter of timing.
About
Stealth by design
We are a four-engineer team with ~20 years of industrial experience on
average — top-tier expertise across logistics, industry and software, plus
advanced analytical engineering beyond ML: systems, optimization, numerical methods, signal
processing, economics. ML engineering is one capability; our rarer edge is the combination.
We are results-oriented and realistic — engineering that works and can be
measured, not academic abstraction.
We are in stealth to protect our IP while a method patent application is in preparation. Full technical disclosure and team
introductions are available under NDA to qualified investors and partners. Don't
trust us — run it: our headline numbers regenerate from sealed, pre-registered result files.
Our ambition is global and our mindset is borderless — we're open to the
right strategic partners, investors and support wherever in the world they are.
Türkiye is our R&D base and cost-talent root, not a ceiling. We are investment-ready and
can incorporate cleanly the moment the right partner and terms appear.
Investors · partners
Fund the experiment that de-risks the thesis
We measured rational's parameterless-stability, drop-in / zero-param, capability-per-dollar
and modest edge at a 200M-token diagnostic scale. The support we're seeking — compute, capital,
the right partner — lets us validate at 3B with a Chinchilla-sufficient budget.
We expect that run to prove our difference from vanilla more clearly and bring our capabilities into the open:
we expect the edge over vanilla to hold — and we'll learn whether it comes from the nonlinearity or from learning-rate headroom;
the first real test of our downstream-capability and calibration / abstain (anti-hallucination) hypotheses — behaviour we hypothesise (not yet demonstrated — a controlled test was an honest null) might set rational apart, which we simply haven't been able to measure yet;
it turns provisional signal into production-grade evidence.
A virtual data-room — full technical brief, internal raw-log evidence chain, team intros — opens under NDA.
Request the technical brief
NDA-gated. Email us and we’ll reply from a Tetracta address to arrange access.
No mechanism is shared before an NDA. Effects & methodology are public above.
Contact
Let's talk
Anonymous in public, but ready for online meetings with qualified counterparts.
Tell us who you are and we'll share what's appropriate — under NDA where it matters.
Investors & partners: the 3B-validation brief, results and team intros — under NDA.
Customers: book a pilot (custom model, RAG / SFT, data & digital-twin, quant).
Researchers: methodology and an honest discussion of what's proven and what isn't.